昨天提到NameNode還有講解裡面存放的檔案代表什麼意思,接著來補上DataNode的部分,如同前面所提Hadoop是master/slave架構,datanode是可以一直擴展,也代表hdfs可以放更多的檔案。
今天也會補充為什麼可以確保檔案不會遺失~
首先來看到datanode上的目錄結構
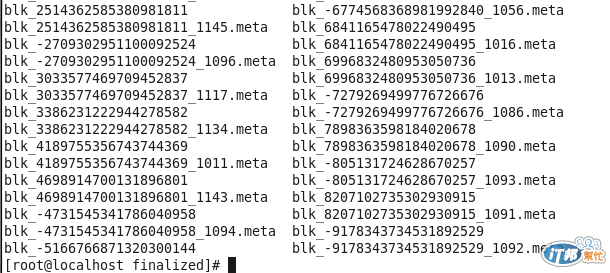
datanode上的current目錄下,存放所有檔案的block,並且以blk_* 的方式來命名。
檔案有兩種類型,一種是blk_*,另一種是blk_*.meta,前者為檔案區塊的內容,後者為描述該區塊的metadata檔。前幾天有MapReduce的範例,其中有放一個1.1GB的檔案,被分成9個區塊(128MB),我拿其中一個區塊做講解,-9178343734531892529,
他在datanode區塊上的檔案名稱叫做blk_-9178343734531892529,metadata為
blk-9178343734531892529_1092.meta。
metadata裡面存放的就是block的資訊。

可以看到<replicas></replicas>
這裡會放<replica><host_name>其中host_name就代表該block有存放在哪個datanode,該block有沒有損壞。
如果有損壞的話,當block的複本數低於設定的複本值時,這時候HDFS會呈現一個不穩定的狀態,這個時候就必須要求HDFS要把所有檔案的block複本數增加到所設定的複本策略數量。
正常來說不太有可能一次壞三台電腦,所以三個複本數應該是足夠了。
不過NameNode掛掉就另當別論了,所以namenode上的fsimage和edits的保存就非常重要,目前的HA機制都是將這兩個檔案存放在安全的NFS上。



 iThome鐵人賽
iThome鐵人賽